How do I create a Hive table from parquet?
 Andrew Mccoy
Andrew Mccoy 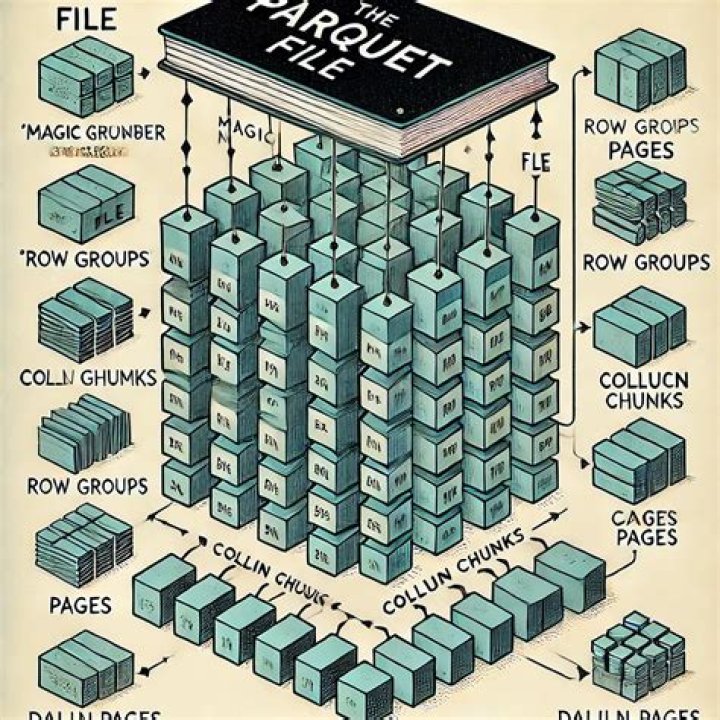
Create Table with Parquet, Orc, Avro - Hive SQL
- Create table stored as Parquet. Example: CREATE TABLE IF NOT EXISTS hql.customer_parquet(cust_id INT, name STRING, created_date DATE) COMMENT 'A table to store customer records.' ...
- Create table stored as Orc. ...
- Create table stored as Avro. ...
- Install Hive database. ...
- Run query.
How do I create a hive table from a Parquet file?
We need to use stored as Parquet to create a hive table for Parquet file format data.
- Create hive table without location. We can create hive table for Parquet data without location. ...
- Load data into hive table . ...
- Create hive table with location.
Does Hive support Parquet?
Parquet is supported by a plugin in Hive 0.10, 0.11, and 0.12 and natively in Hive 0.13 and later.How do you create a table in Parquet format?
To make the new table also use Parquet format, include the clause STORED AS PARQUET in the CREATE TABLE LIKE PARQUET statement. If the Parquet data file comes from an existing Impala table, currently, any TINYINT or SMALLINT columns are turned into INT columns in the new table.What is Parquet file in hive?
Share. Apache Parquet is a popular column storage file format used by Hadoop systems, such as Pig, Spark, and Hive. The file format is language independent and has a binary representation. Parquet is used to efficiently store large data sets and has the extension .Hive tutorial - create table, create table like, stored as textfile, stored as parquet
How are Parquet files stored?
Parquet files are composed of row groups, header and footer. Each row group contains data from the same columns. The same columns are stored together in each row group: This structure is well-optimized both for fast query performance, as well as low I/O (minimizing the amount of data scanned).How do I view parquet files in HDFS?
Article Details
- Prepare parquet files on your HDFS filesystem. ...
- Using the Hive command line (CLI), create a Hive external table pointing to the parquet files. ...
- Create a Hawq external table pointing to the Hive table you just created using PXF. ...
- Read the data through the external table from HDB.
How do you load data on a parquet table?
Load CSV file into hive PARQUET table
- Step 1: Sample CSV File. Create a sample CSV file named as sample_1. ...
- Step 2: Copy CSV to HDFS. ...
- Step 3: Create temporary Hive Table and Load data. ...
- Step 4: Verify data. ...
- Step 5: Create Parquet table. ...
- Step 6: Copy data from a temporary table. ...
- Step 6: Output.
What is difference between parquet and Delta?
Delta is storing the data as parquet, just has an additional layer over it with advanced features, providing history of events, (transaction log) and more flexibility on changing the content like, update, delete and merge capabilities. This link delta explains quite good how the files organized.Does Parquet file have schema?
Overall, Parquet's features of storing data in columnar format together with schema and typed data allow efficient use for analytical purposes. It provides further benefits through compression, encoding and splittable format for parallel and high throughput reads.Why is Parquet faster?
Parquet is built to support flexible compression options and efficient encoding schemes. As the data type for each column is quite similar, the compression of each column is straightforward (which makes queries even faster).What is difference between ORC and Parquet?
ORC files are made of stripes of data where each stripe contains index, row data, and footer (where key statistics such as count, max, min, and sum of each column are conveniently cached). Parquet is a row columnar data format created by Cloudera and Twitter in 2013.How do I load a parquet file in Spark?
The following commands are used for reading, registering into table, and applying some queries on it.
- Open Spark Shell. Start the Spark shell using following example $ spark-shell.
- Create SQLContext Object. ...
- Read Input from Text File. ...
- Store the DataFrame into the Table. ...
- Select Query on DataFrame.
What is difference between Hive and Impala?
Apache Hive might not be ideal for interactive computing whereas Impala is meant for interactive computing. Hive is batch based Hadoop MapReduce whereas Impala is more like MPP database. Hive supports complex types but Impala does not. Apache Hive is fault-tolerant whereas Impala does not support fault tolerance.What is Avro file format in Hive?
hive File formats in HIVE AVROAvro files are been supported in Hive 0.14. 0 and later. Avro is a remote procedure call and data serialization framework developed within Apache's Hadoop project. It uses JSON for defining data types and protocols, and serializes data in a compact binary format.